Pour comprendre le fonctionnement d’une IA, on doit prendre en compte deux étapes qui se succèdent :
- l’entrainement du système d’IA ;
- l’utilisation par le grand public.
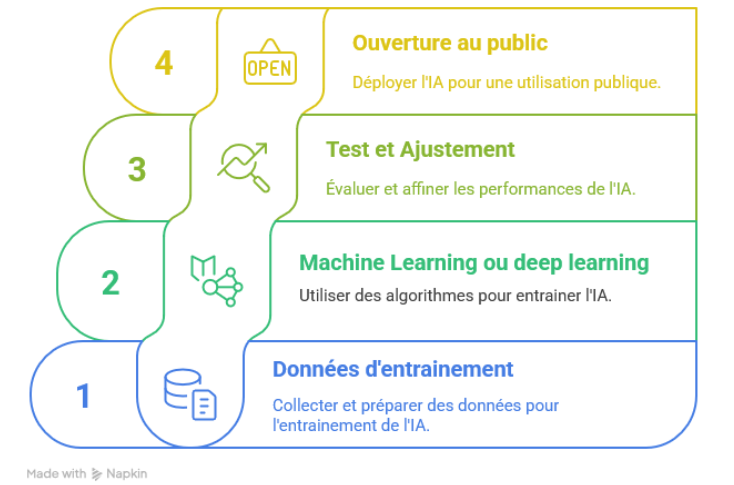
Infographie sous forme de colonnes horizontales empilées montrant une progression de 1 à 4 :
– 1. Données d’entrainement : collecter et préparer des données pour l’entrainement de l’IA
– 2. Machine learning ou deep learning : utiliser des algorithmes pour entrainer l’IA
– 3. Test et ajustement : évaluer et affiner les performances de l’IA
– 4. Ouverture au grand public : déployer l’IA pour une utilisation publique
Lors de la phase d’entrainement, les choix des entreprises et de ses ingénieurs s’expriment à plusieurs niveaux :
- Sélection des données d’entrainement / Structuration ou tokenisation et vectorisation.
- Le choix du modèle d’apprentissage (et donc le rôle de l’humain).
- Test et ajustement (place de l’humain).
- Choix des paramétrages accessibles selon les profils (freemium, payant, etc.).
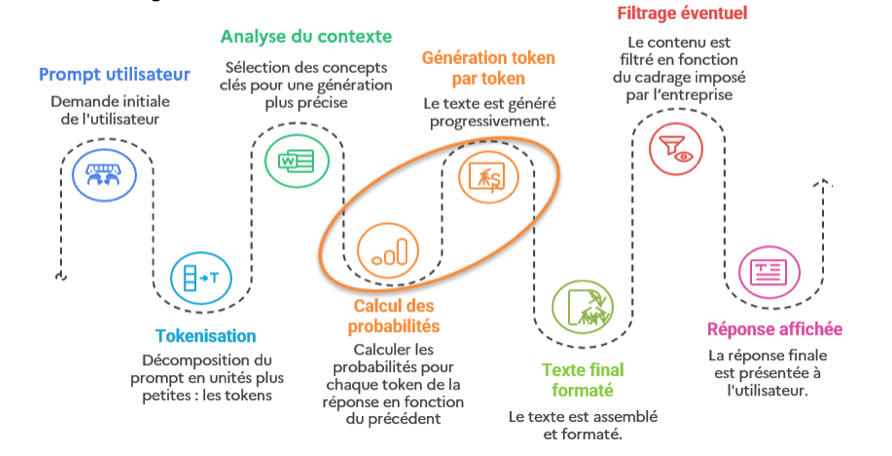
L’image présente un schéma en six étapes décrivant le fonctionnement d’un modèle de génération de texte, comme une intelligence artificielle. Voici la transcription complète et structurée de chaque étape, dans l’ordre de gauche à droite :
1. Prompt utilisateur (en bleu)
– Description : Il s’agit de la demande initiale formulée par l’utilisateur.
2. Tokenisation (en bleu clair)
– Description : Le prompt est décomposé en unités plus petites appelées « tokens ».
3. Analyse du contexte (en vert)
– Description : Sélection des concepts clés pour permettre une génération plus précise du texte.
4. Calcul des probabilités (en orange)
– Description : Calcul des probabilités pour chaque token de la réponse, en fonction du token précédent.
5. Génération token par token (en orange)
– Description : Le texte est généré progressivement, token par token.
6. Texte final formaté (en vert clair)
– Description : Le texte est assemblé et formaté.
7. Filtrage éventuel (en rouge)
– Description : Le contenu généré est filtré selon les règles ou le cadrage imposé par l’entreprise.
8. Réponse affichée (en rose)
– Description : La réponse finale est présentée à l’utilisateur.
Chaque étape est illustrée par une petite icône et reliée par une ligne pointillée, formant un parcours logique du début (demande de l’utilisateur) à la fin (réponse affichée). Une ellipse orange met en évidence les étapes « Calcul des probabilités » et « Génération token par token ».
Lors de la phase de génération, les choix des entreprises et de leurs concepteurs s’expriment à plusieurs niveaux :
- La tokenisation et le contexte : sont liés au choix des découpages des mots, aux concepts et notions.
- Le calcul des probabilités : dépend des paramètres définis par l’entreprise (de quelques milliards à plusieurs centaines milliards).
- La génération token par token : dépend de la part d’aléatoire définie par l’entreprise.
- Le filtrage éventuel : imposé par l’entreprise ou un État.
Ainsi, une IA générative n’est pas neutre dans ses réponses. Il est donc important de toujours conserver un regard critique sur les productions des IA génératives.
Pour avoir les définitions des termes techniques, on peut se rapporter à l’article « Comment une IA générative crée-t-elle du texte »
Module en auto-formation
Module CREIA : « Génération de textes : communiquer efficacement avec une IA (Vittascience)
Ressources complémentaires
Article de la Drane IdF « Comment une IA générative crée-t-elle du texte ? »